Pela primeira vez, sistemas de IA não estão só lendo a web: estão transacionando nela. E um agente de compras legítimo se parece, byte a byte, com uma fraude automatizada.
A pergunta "é bot ou humano?" parou de funcionar
Por anos, a defesa de qualquer site se apoiou numa pergunta binária: esse tráfego é de gente ou de robô? Robô levava bloqueio, gente passava. Funcionava.
Não funciona mais. Em 2025 o tráfego automatizado cresceu oito vezes mais rápido que o humano, e o tráfego de IA especificamente subiu 187% no ano, segundo o relatório da HUMAN Security sobre tráfego de IA e agêntico. A novidade não é o volume. É o que esse tráfego faz: agentes de IA agora navegam, preenchem formulário, comparam produto e fecham compra sozinhos, sem ninguém do outro lado clicando.
E aí o velho sinal de alarme vira ruído. Navegação rápida, checkout automático, formulário preenchido em milissegundos: tudo isso antes denunciava ataque. Hoje pode ser só o assistente de compras de um cliente real.
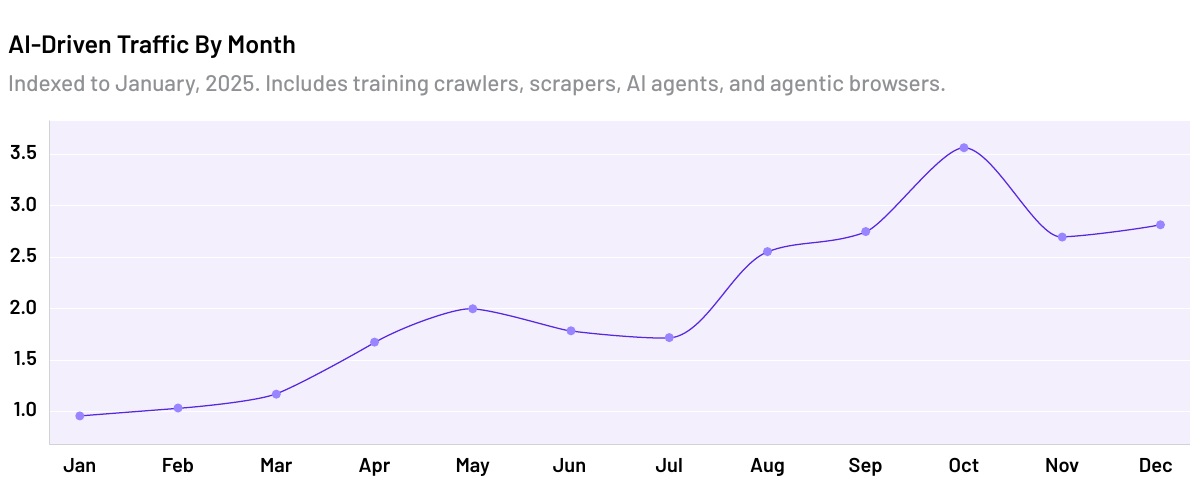
Tráfego gerado por IA mês a mês em 2025, indexado a janeiro. Fonte: HUMAN Security, 2026.
Nem todo tráfego de IA é igual
Tratar "tráfego de IA" como uma coisa só é o primeiro erro. São três coisas diferentes, com riscos diferentes.
- Crawler de treino — coleta dado em massa para treinar modelo. É a maior fatia, 67,5%.
- Scraper — extrai dado específico e atual para alimentar busca e comparação em tempo real. 31,9%.
- Agente autônomo — navega, preenche, gerencia conta e executa transação por conta própria. Ainda é pequeno, cerca de 1,7% do tráfego de IA, mas cresceu 7.851% em um ano.
O agente autônomo é a fatia minúscula que muda o jogo. Crawler e scraper leem. O agente age. E é a ação de criar conta, trocar senha ou tentar um pagamento que carrega peso financeiro.
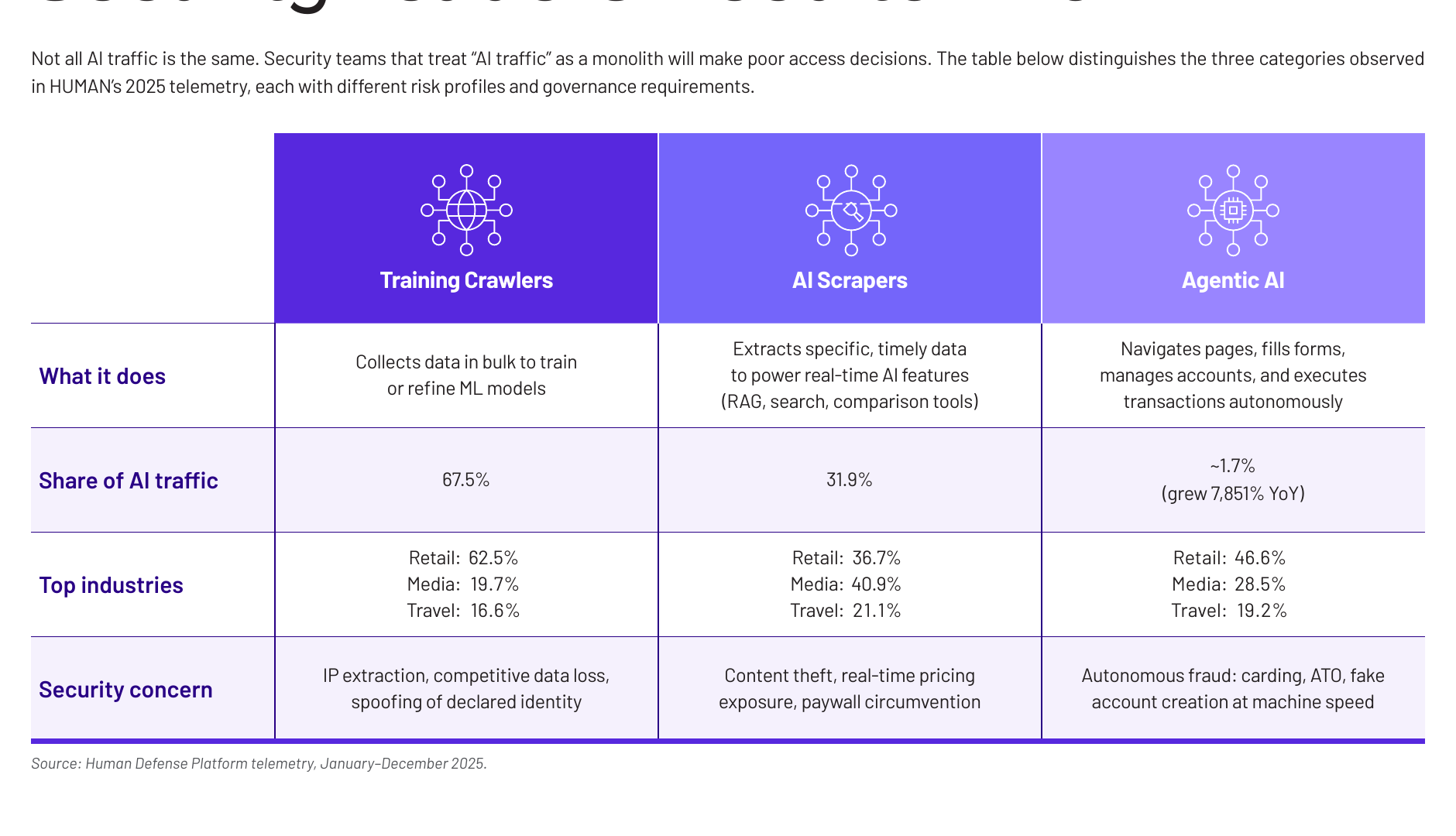
Os três tipos de tráfego de IA, participação e risco associado. Fonte: HUMAN Security, 2026.
Por que o crachá não vale mais nada
A reação intuitiva é deixar passar os bots bons e barrar o resto. O problema é como você sabe quem é bom.
O método padrão olha o user-agent, a string que o tráfego usa para se identificar: "sou o bot de busca da empresa tal". Só que essa string é texto livre. Qualquer um escreve qualquer coisa nela. Boa parte do tráfego que se declara bot conhecido não vem da infraestrutura desse bot. É atacante se passando por crawler confiável para burlar a sua allowlist no robots.txt. O crachá é falsificável, e gente mal-intencionada falsifica.
Enquanto isso, a fraude foi para o mesmo lugar que o comércio. O relatório registrou uma média de 402 mil tentativas de comprometimento de conta pós-login por organização, quatro vezes mais que no ano anterior. Cerca de 20% de todo o tráfego já é tentativa de scraping. Criação de conta falsa subiu 89%. E aqui está o número que resume tudo: apenas meio por cento separa a automação que ajuda da automação que ataca. A margem é fina demais para decidir no olho.
O que muda na sua defesa
Os dois extremos são armadilha. Bloquear todo tráfego automatizado fecha a porta para receita, porque clientes que chegam por resposta de IA convertem mais e esse canal só cresce. Liberar tudo é absorver fraude na veia.
O caminho não é perguntar se é robô. É perguntar se a interação é confiável, independente de vir de pessoa, agente ou navegador automatizado. Na prática, isso exige três coisas que a maioria das defesas não tem hoje.
Saber quem é o ator de verdade, além do que ele diz ser. Olhar a sessão inteira, não a ação isolada: uma troca de senha é inofensiva, a menos que venha depois de dez tentativas de login falhas. E ajustar o controle em tempo real, apertando ou afrouxando conforme o comportamento, em vez de um carimbo de "confiável" dado uma vez e para sempre.
É confiança por intenção, não por identidade declarada. E ela só funciona se você tiver visibilidade do tráfego de IA que entra nas suas aplicações, coisa que hoje quase nenhuma empresa tem.
Fonte: The CISO's Guide to AI and Agentic Traffic, HUMAN Security, 2026.